The IHOP-ification of AI generated unleavened bread
Does OpenAI have a secret agenda to flatten the world’s rich collection of unleavened breads into the bland, American pancake?


I have spent too many hours over the last couple weeks trying to get OpenAI’s image generation system to return me a picture of Swedish pancakes.
It all started when I demoed ChatGPT to my grandmother. She was impressed by its knowledge of American history, but when we got to the image generation capabilities, it botched her request for “a plate of Swedish pancakes with lingonberry sauce.” No amount of prompt manipulation could get it to return anything but fluffy American pancakes smothered in a goopy raspberry sauce.
My grandmother was understanding, and we moved on to talking about how she makes Swedish pancakes (you can find her recipe below), but as a 5th generation half-Swede who works in AI, I was peeved.
First, some background. Swedish pancakes are a thin, sweet pancake, often served rolled up and topped with lingonberry sauces. They are flatter than American pancakes, egg-ier than French crepes and are produced in large quantities each September at New Jersey’s annual Scandinavian Festival.
A Google image search for “Swedish pancakes” returns thousands of images of the dish:

And yet, OpenAI’s image model (named DALL-E X, we’re currently in the reign of DALL-E 3), consistently produced images like this:


On a scale of algorithmic bias where 0 is Fun For The Family, 5 is Racist But Unlikely To Cause Real World Harm and 10 is Hurts People In A Material Way, this doesn’t rise above a 1. But it did pique my interest.
My first hypothesis was that Sweden, the 86th largest country with a relatively small colonial empire, doesn’t have the same digital footprint as America, the 3rd largest country, which exports its culture around the world. Some fraction of every pancake that is produced is photographed, some fraction of those photographs are uploaded to the internet and some fraction of those end up in the training data of generative image models.
That’s a fine hypothesis, and while OpenAI does not disclose the training data for DALL-E, it is almost certainly true that they are training on more photos of American pancakes than Swedish pancakes. But it doesn’t fully explain the problem.
France has over 6 times the population of Sweden, yet DALL-E returned what can only be described as a tall stack of crêpes.

Perhaps most perplexing were DALL-E images of the Indian dishes roti and naan. On the left is some AI generated roti served alongside eggs (roti, unlike American pancakes, are not made with eggs,) and on the right is AI generated naan with a large pat of non-clarified butter. India is the world’s most populous country, with roughly 130 times the population of Sweden.

Does OpenAI have a secret agenda to flatten the world’s rich collection of unleavened breads into the bland, American pancake?
Hypothesis 1: A Nefarious Betty Crocker lobby
It’s impossible to prove or disprove any hypothesis because OpenAI does not release its image models, the data that was used to train them or the business logic that surrounds the DALL-E chat interface. There are papers about the various OpenAI models, but the descriptions of how they collected the training data are so cryptic, that even a team with a lot of time and a lot of money wouldn’t be able to recreate it. Not to play the AI safety card, but it would be a lot easier to understand the bread bias of DALL-E if their models were open source.
Hypothesis 2: Prompt expansion
OpenAI lets users generate images with DALL-E through a chat interface on its website and mobile app, but these tools are not simple wrappers on the underlying model. For example, the system will edit requests for images of women in bathing suits (a problem we ran into when generating the artwork for Bassey’s piece on AI-generated porn).
In fact, OpenAI seems to alter almost all user prompts, even the ones that are above board. I assume they’ve found that the prompts with more precise details yield better results and producing different versions of a prompt allows them to return multiple different interpretations of a prompt instead of four nearly identical images.
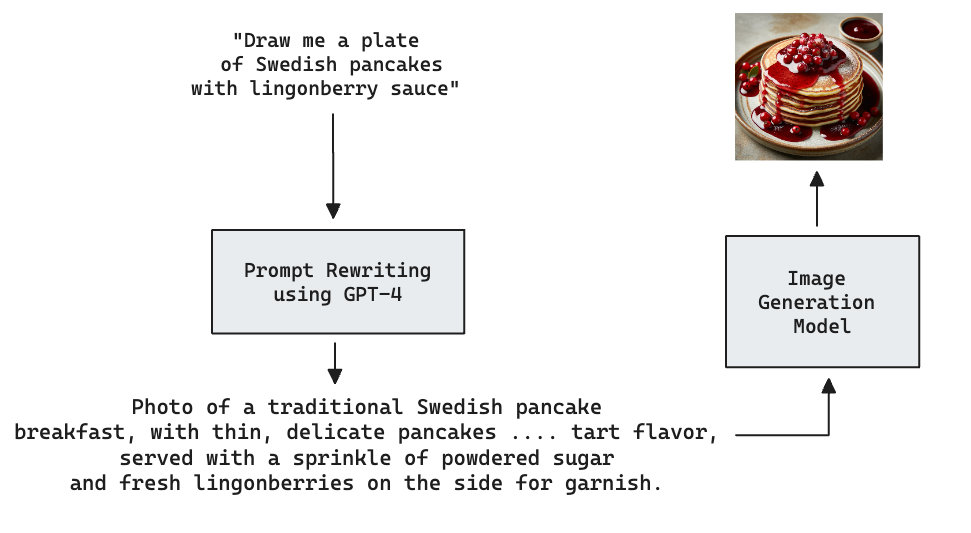
I was pleasantly surprised to find that they surface the rewritten prompts. My initial request to “Draw me a plate of Swedish pancakes and lingonberry sauce” was augmented with requests for the pancakes to be styled with steaming cups of coffee, silver forks, and breakfast scones.

This prompt expansion system uses OpenAI’s GPT-4 language model to generate additional prompts. The prompt they use to do this, the meta-prompt you could say, was recently leaked. Reading through it reminded me of the futile attempts of The Plaza staff to prevent Eloise from vandalizing their luxury hotel. You must put the turtle on a leash. Also no red crayons, or purple crayons...or any crayons!
I suspect that some of my prompts were rewritten to add language that pushed the image model toward drawing American pancakes. My request for roti and crepes were rewritten to be a “stack of roti bread” and a “stack of freshly made French crepes” respectively. And “naan” was replaced with “butter naan,” which is a style of naan, but perhaps too subtle a distinction for the model to understand. Sure enough, when I wrote my own long, detailed prompts without references to “stacks” or “butter,” I got back much more accurate representations of the bread.

I should note that OpenAI seems to be iterating a lot of this meta-prompt and I can no longer reproduce my examples of Americanized naan or crepes… But I still can’t get DALL-E to draw me Swedish pancakes.
Hypothesis 3: Training Data
Now that I have a guess at what’s happening with crepes and naan, I’ve landed back on my original hypothesis that the DALL-E model hasn’t been trained on many examples of Swedish pancakes. Unfortunately for my search for the culprit, OpenAI’s image generation pipeline includes at least three different models.
We’ve already dug into the GPT-4 model they use to rewrite the prompts; that’s a large language model (LLM) that takes a text prompt and outputs a text response. I asked GPT-4 to tell me about Swedish pancakes, and it gave me a friendly, accurate response. So that’s not the problem.
There is also the image generation model that takes in a text prompt and produces an image. A subset of that model is yet another model (sorry!) that takes in your prompt and translates it into a list of numbers, known as embeddings.
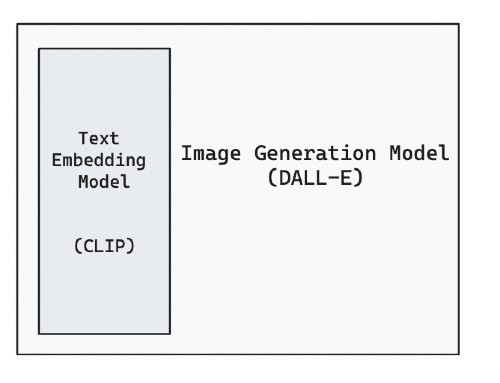
It makes sense that a model that creates images from text needs to have an understanding of language, particularly language that tends to be used when describing images. An effective way to build that is to train a model that can produce “useful” numeric representations of text and then use those representations to encode the input prompt to the image generation model.
The model OpenAI uses to represent text is called CLIP, and it’s trained to be able to match image captions to the images they came from. CLIP embeddings have proved broadly useful across all sorts of image and language applications.
OpenAI has made the CLIP model open source, so we can use it to generate embeddings of our breads. The absolute position of the words in the visualization below is arbitrary, but the relative position can give us some intuition about what entities the model thinks are similar to each other.
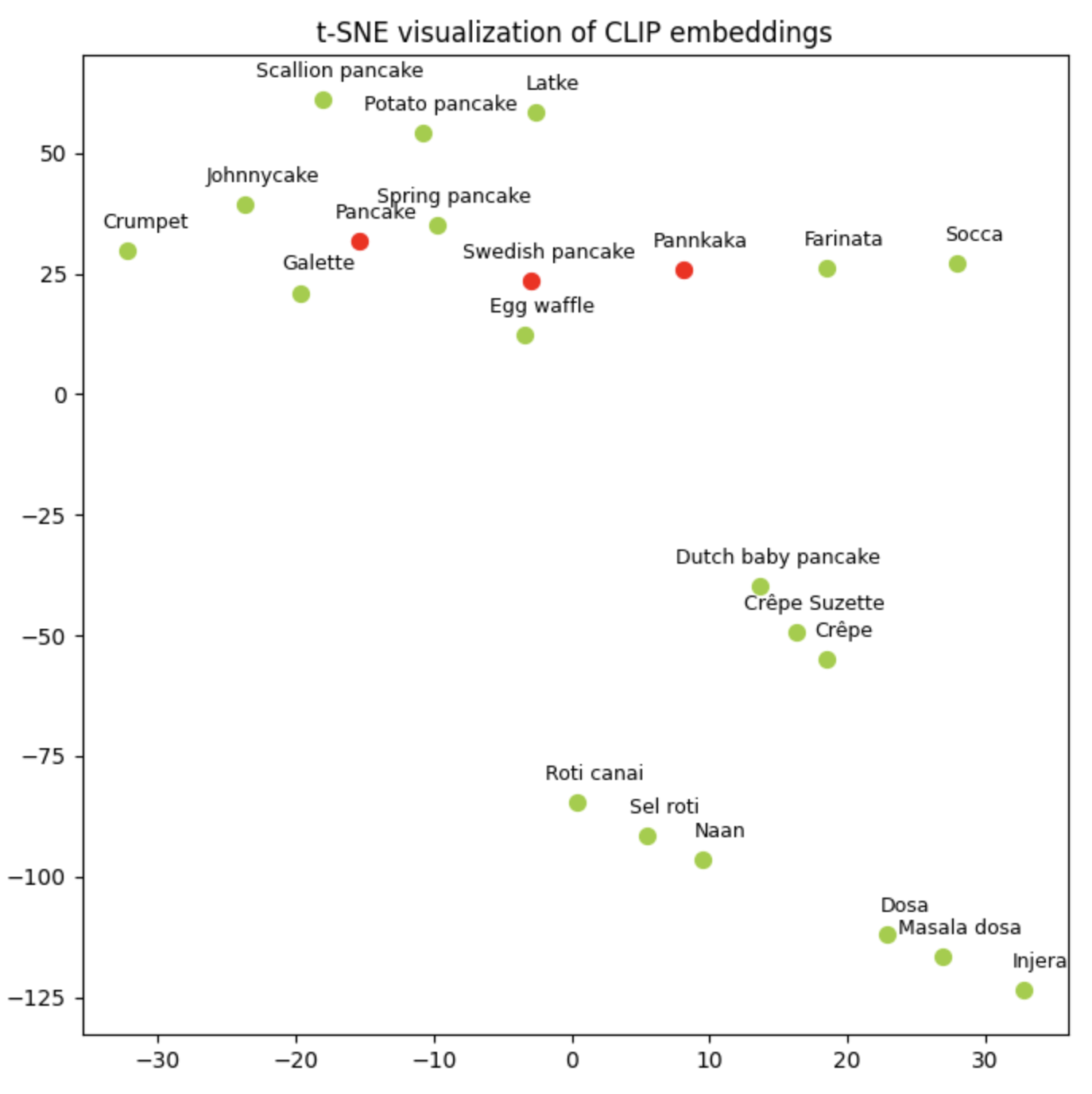
It appears that the CLIP model has learned that ‘Swedish pancake’ and ‘pancake’ are fairly similar to each other. Could CLIP be confusing my request for “Swedish pancakes” with requests for pancakes?
To test this hypothesis, I asked DALL-E for images of other unleavened breads close to “pancake” in CLIP space. I got back reasonable potato pancakes, johnnycakes and galettes, but my spring pancakes were wild. (Spring pancakes are thin, pliable pancakes traditionally served with Peking duck).

Based on my very unscientific experiments, my conclusion is that the text models that are part of the image generation pipeline do encode the concept of Swedish pancakes, but the image model hasn’t seen enough (if any) examples to be able to create an accurate image of them. The same problem is likely afflicting my poor spring pancake.
The importance of representation in training data
Several years ago, Google Research ran a project to collect images from around the world to build a more “inclusive” image dataset. At the time they wrote,
A system trained on a dataset that doesn’t represent a broad range of localities could perform worse on images drawn from geographic regions underrepresented in the training data.
They used a crowdsourcing app to collect submissions and released the Open Images Extended dataset in 2018. Over 80% of the images in that dataset come from India, so not a perfect distribution from the world’s countries, but a step in the right direction to diversify image training data away from the western culture.
With that, here is my grandmother’s recipe for Swedish pancakes and a photo of her using ChatGPT. If you make it, please take a picture and put it on the internet.
You can reach us at hello@machinesonpaper.com if you encounter any bread bias from your culture. We’d love to hear from you!
Swedish Pancake Recipe, from Bernice Hanson
- 1 cup flour
- 2 tbsp sugar
- 1/4 tsp salt
- 3 eggs
- 3 cups milk
Steps
- Sift flour into bowl, add sugar and salt.
- Add eggs and milk, stirring until well blended. Let stand for 2 hours.
- Heat Swedish pancake pan (or ordinary pancake pan) and butter well. Beat batter again.
- Pour several tsps into a section of pan and fry on both sides until nicely brown.
- Place on a very hot platter and serve immediately with lingonberries.







Comments
Sign in or become a Machines on Paper member to join the conversation.
Just enter your email below to get a log in link.